
通用技术“金融数据魔方” :赋能集团数字金融智慧治理升级
1、公司介绍
中国通用技术(集团)控股有限责任公司(简称“通用技术集团”)成立于1998年3月,是中央直接管理的国有重要骨干企业,2018年获批成为国有资本投资公司试点企业。集团聚焦先进制造与技术服务、医药医疗健康、贸易与工程服务三大核心主业,业务覆盖全球100多个国家和地区,拥有6家上市公司(沈阳机床、环球医疗、中国医药等),7次入围《财富》世界500强。通用技术财务公司(以下简称“公司”)成立于2010年9月,作为内部银行和集团司库管理平台,是集团内唯一持牌金融机构,承担集团资金中心职能,托管集团境外资金管理平台——香港资本公司和集团统保实施平台——保险经纪公司。
2、项目背景
随着通用技术集团产业数字化和管控数字化的推广应用,集团公司积累了海量的财务资金管理相关领域的数据资产,数据资产蕴含的价值有待进一步发挥。数据治理是一项涉及集团各层级企业、各部门的复杂的系统工程,由于缺乏专业的数据治理组织、数据孤岛的存在导致数据在不同部门或系统之间不能有效地共享或交换、缺乏数据质量问题的跟踪闭环管理和考核评价机制,导致数据治理工作推进困难,防范资金风险缺乏有效的抓手,数据价值未能有效发挥,数据应用效果距离优秀的企业还有较大差距。
3、项目实施方法
通用技术金融数据治理遵循DAMA数据管理框架,开创性地总结了适合公司内外部环境的数据治理方法论Rasas(注:来自印度哲学的词语,被视为艺术作品的核心)。Rasas的五个首字母代表数据治理的五个步骤,Rule(规)、Administrate(管)、Storage(聚)、Algorithm(算)、Service(服),依次通过上述五个步骤,将海量的碎片化数据加工为高质量的数据艺术作品——数据资产,实现数据资产共享。
3.1数据之“规”,建制度(Rule)
数据标准规范主要包括“管理标准”和“数据标准”两类:“规”章,成立数据治理委员会,制定数据管理制度;“规”范,制定参考数据、主数据、元数据、数据质量的标准规范。
数据治理委员会组织各部门编制本业务域的数据标准规范并在相应的业务系统中贯标。
3.2数据之“管”,强管理(Administrate)
“管”主要是数据的治理和管理,结合数据平台技术支撑,运用行之有效的治理手段,配合完善的数据管控机制,实现对数据的全生命周期管理,最终得到可共享复用的、标准化的、高质量的数据资产。
3.3数据之“聚”,聚资源(Storage)
在金融数据中台中配置各业务系统的数据源,将各个业务系统中的结构化数据和非结构化数据,采集汇聚至数据中台,实现数据入湖存储,并对入湖数据按照数据质量标准进行数据质量校验。
3.4数据之“算”,建模型(Algorithm)
通过配置可视化数据加工流程,对入湖数据进行清洗、汇聚、转换、联结、维度和度量扩展等一系列数据算法,形成数据资产。数据资产按照业务域划分,以资产目录方式进行可视化发布上架、浏览、订阅。
3.5数据之“服”,享价值(Service)
数据服务管理,发布数据资产共享服务API,实现多系统、多主体数据资产服务共享,并监控数据服务过程日志。
4、实施路径
通用技术金融数据治理遵循Rasas五步法,开展数据治理实施工作,具体实施工作如下。
4.1数据治理组织架构
公司设立数据管理委员会,数据管理委员会是总经理办公会领导下的决策支持工作机构,数据治理办公室设在计划财务部,向总经理办公会报告工作,负责统筹组织、协调、管理和监督公司数据质量,负责落实数据质量管理工作,推动数据质量提升。
数据管理委员会由分管计划财务部的公司领导任主任,由计划财务部、科技信息部、资金结算部、金融服务部、金融市场部、国际业务部、风险控制与法律合规部部门经理组成。
4.2确定数据标准
组织相关部门确定各类数据标准,并在“金融数据魔方”落地。
(1)参考数据,主要是代码表,参考数据治理的重点是明确责任部门,确保获取一套准确且最新的数据,比如国家地区代码、行政区划代码、币种代码、国民经济行业分类代码等。
(2)主数据,主要是实体数据,主数据治理的重点是确保源头系统主数据的准确性和可用性,比如同路人系统确保客户数据准确性、司库管理系统负责银行账户主数据的准确性。
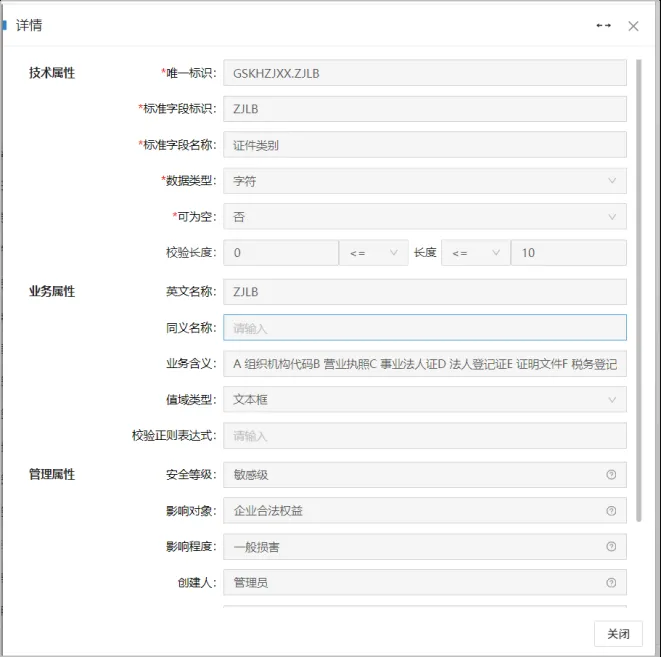
(3)元数据标准,元数据分为业务元数据、技术元数据和管理元数据。其中,业务元数据包括业务含义、有效值域、计算规则等,由业务部门制定;技术元数据描述数据的类型、长度等技术细节,由技术部门制定;管理元数据包括数据管理部门、数据安全等级等信息。
元数据标准包括业务元数据标准、数据资产元数据标准。
(4)数据质量标准,根据国资委报送数据标准规范、金融监管报送数据标准规范确定业务系统源数据的入湖数据质量校验标准和最终形成的数据资产质量校验标准。
4.3数据盘点入湖
依据监管报送数据采集要求、集团决策分析需求和财务公司数据分析需求,盘点三个业务域、六个信息系统中需要纳入数据治理的源数据清单(即确定金融数据治理的边界)。
4.4数据加工
依托“金融数据魔方”,搭建分层数仓。在系统中落地数据采集、数据加工流程,实现源数据采集入湖、数据质量校验、数据资产落地。
4.5数据共享应用
构建数据服务目录,以API接口、数据集、报表、决策分析报告等数据服务形式,实现数据共享和数据应用。
5、项目成果展示
“金融数据魔方”作为公司的金融数据治理平台,承载着公司金融数据治理从源头到应用的整个流程,并在外部监管和内部管理的双重驱动下,不断迭代优化。
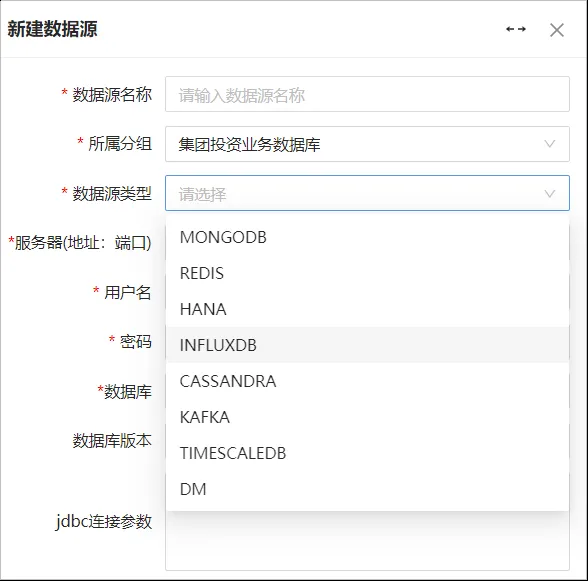
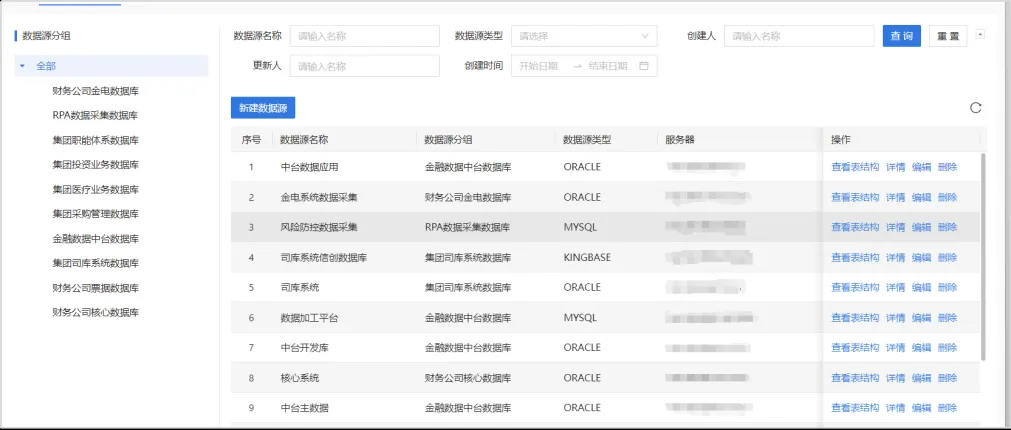
5.1数据源管理
数据源管理,支持多源头、多类型的数据源配置,实现多源头数据采集汇聚。
5.2数据标准管理
数据标准管理模块,实现数据标准的拟定、变更、审核、发布和在线查阅功能,支持历史版本管理。
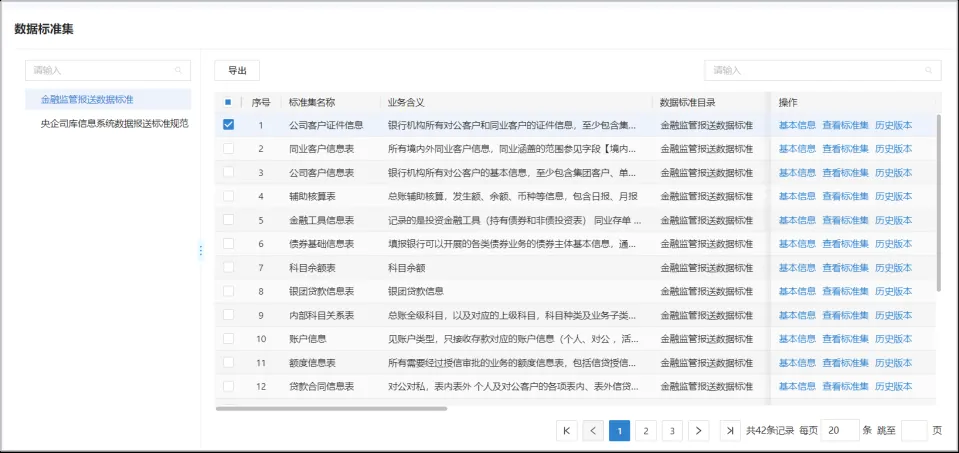
数据标准查看:

数据项标准详情:
5.3元数据管理
元数据管理模块,实现了数仓各层数据的元数据管理。
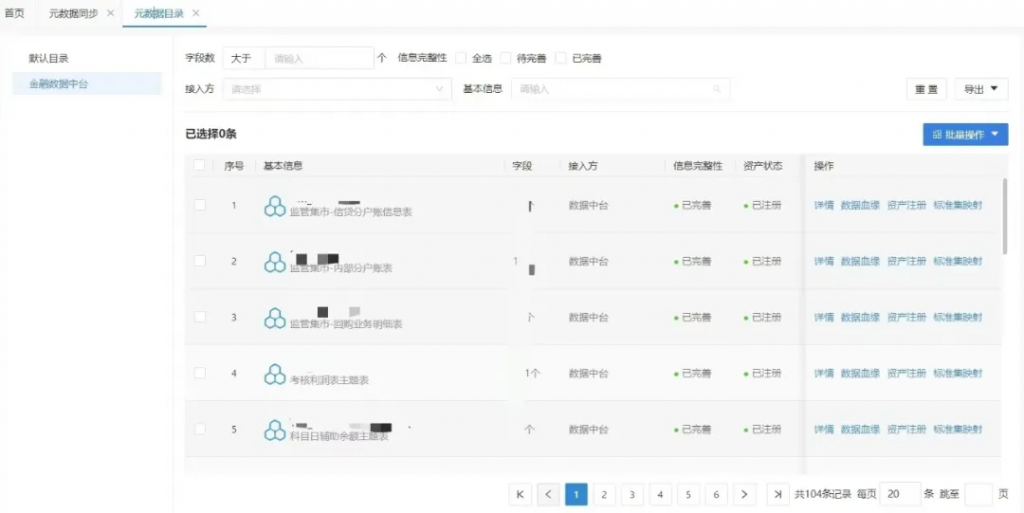
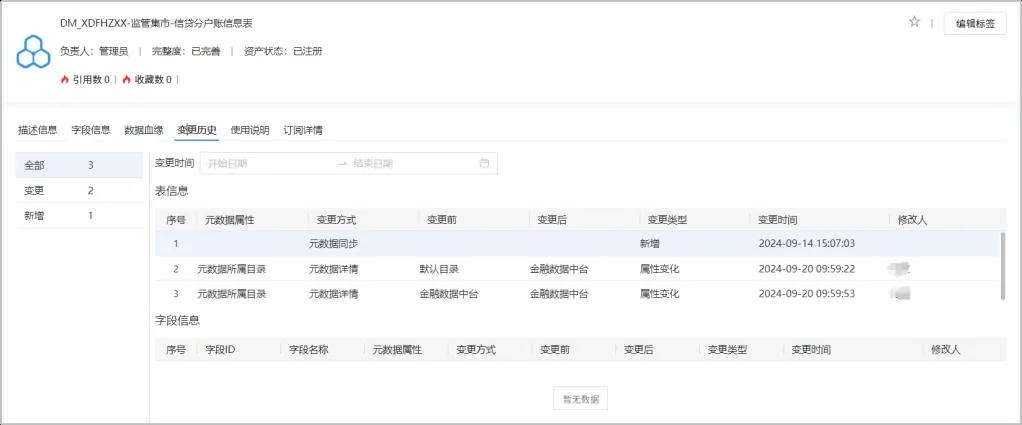
系统通过定期扫描的方式,及时发现元数据的变更,并详细记录元数据的变更日志,包括字段的新增、变更、删除等。
5.4数据质量校验
为了提高数据质量校验规则的可读性和规则配置效率,系统提供两种质量校验规则配置方式。
第一种:简单校验规则,包括字段的非空校验、长度校验、枚举值校验、唯一性校验、数据取值范围合理性校验。此类校验规则通过简单勾选即可完成配置,比如18位机构代码。
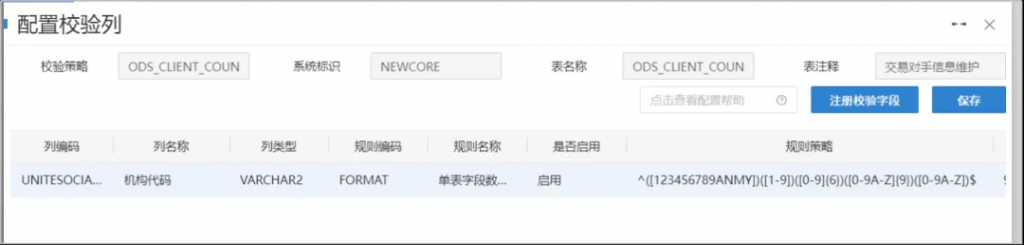
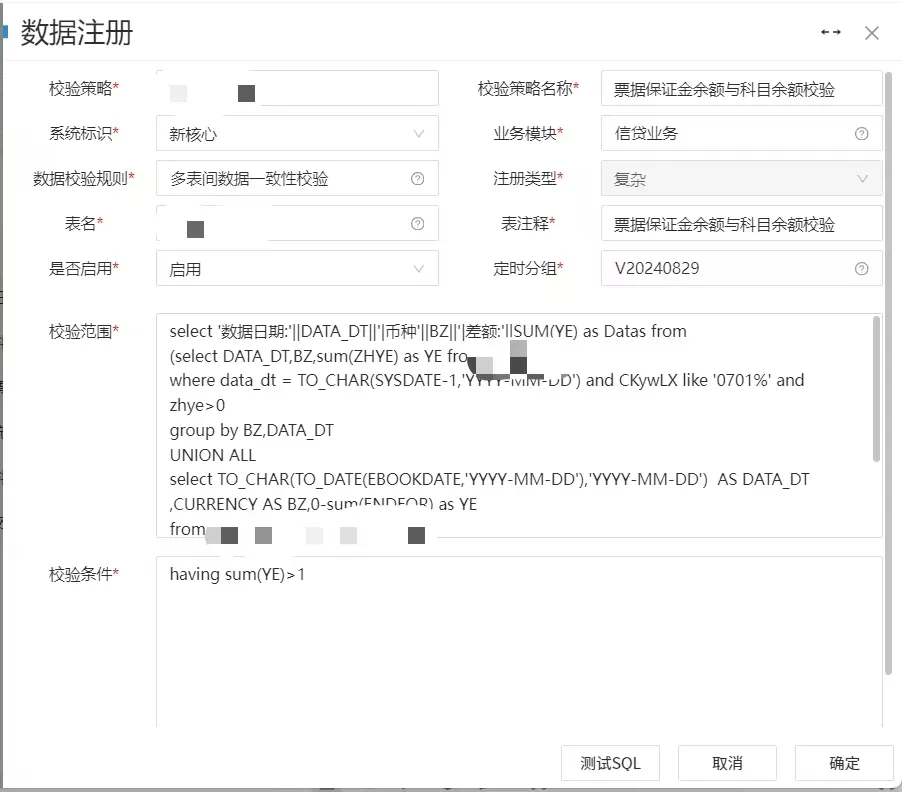
第二种:复杂校验规则,需要编写数据校验脚本,进行单表内多字段之间逻辑校验、多表之间逻辑校验;比如票据保证金余额与科目余额之间的逻辑校验。
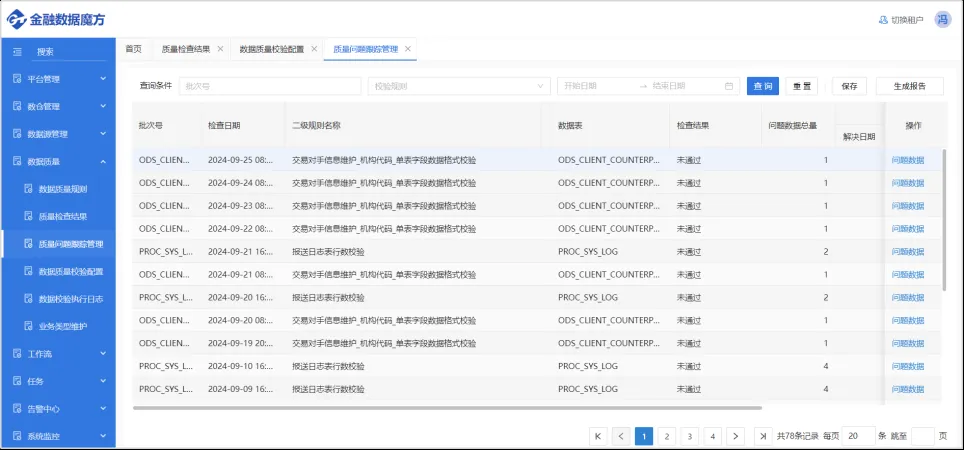
数据质量校验结果:
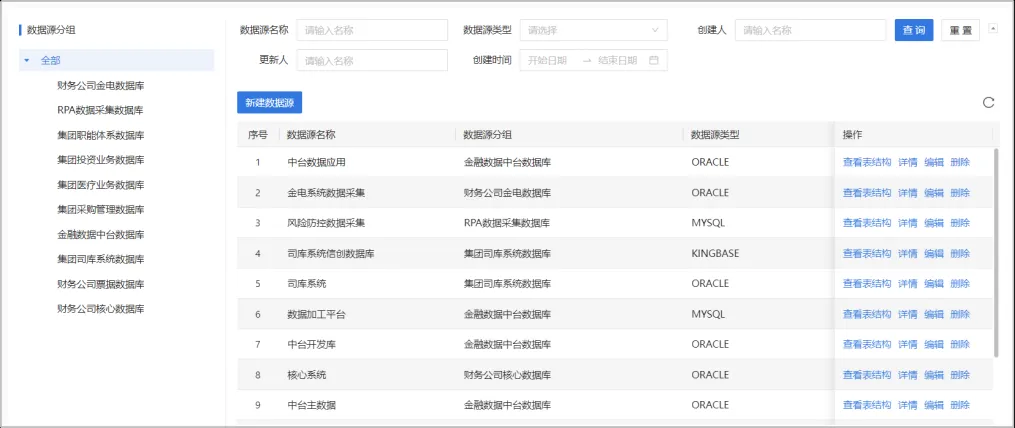
5.5数据采集
采集三个业务域、六个信息系统的源数据。
5.6数据加工
配置数据加工流程实现数据逐层加工(ODS、DWD、ADS、DM)。
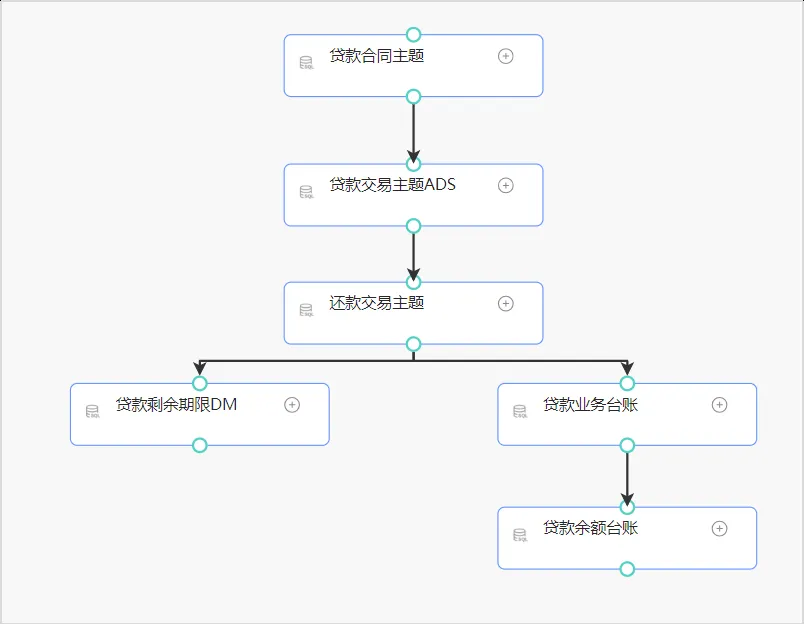
表级数据血缘关系展示:
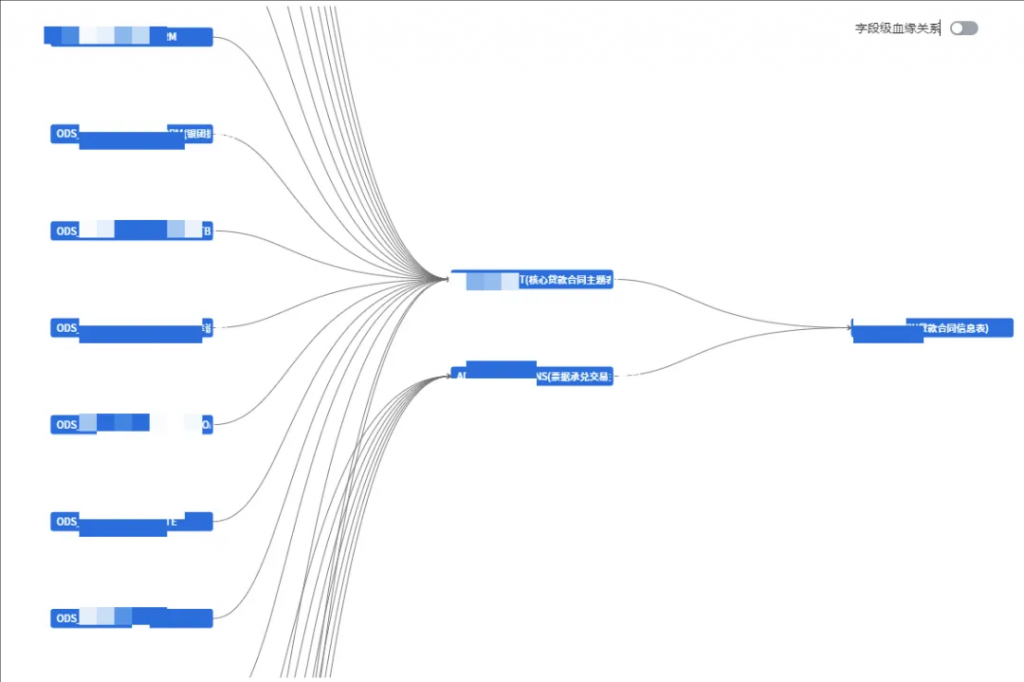
字段级数据血缘关系展示:

5.7数据资产
金融数据中台实现了数据资产目录可视化,并可以联动查询数据资产。
数据资产描述:
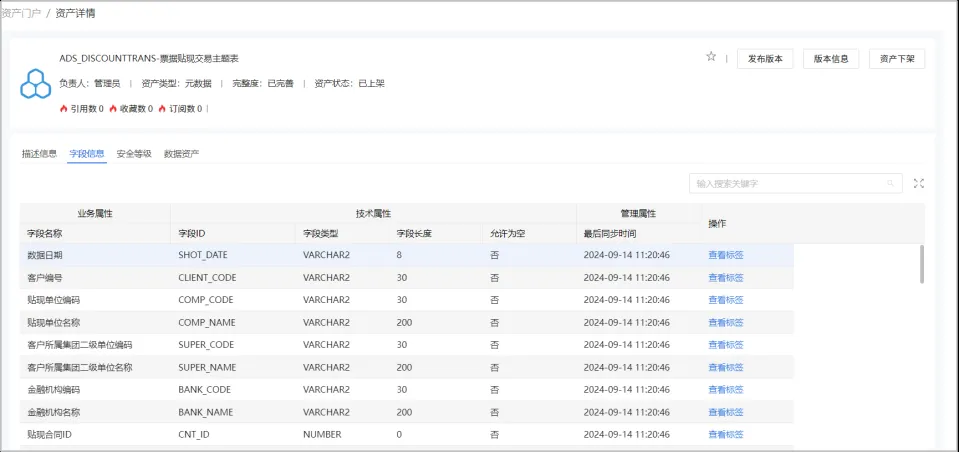
数据资产详情:
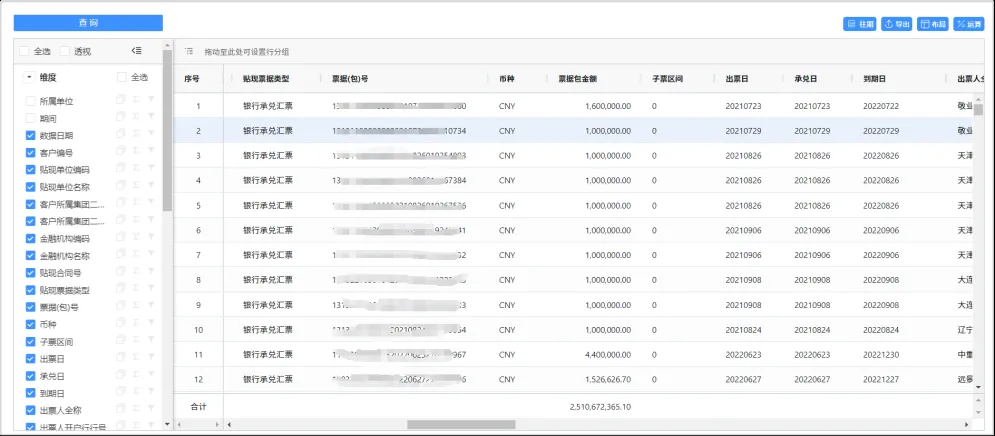
5.8数据共享应用
数据资产通过API接口等方式实现数据共享输入、输出,目前,金融数据中台日均向集团内部各上下游系统分发数据超过20万条。
6、项目创新点
6.1 “数据中台+CIPS”金融标准化创新实践
在传统银企直连模式下,企业集团如果希望与N家银行实现数据交互,需要与直连银行搭建N条专线,开发N种接口。而“数据中台+CIPS”模式,只需要按照CIPS标准开发一次,与CIPS系统搭建一条专线,便可以与N家银行实现间接链接,线上办理业务。
通用技术财务公司作为全国6家试点企业之一,创新性地提出“数据中台+CIPS”模式,通过CIPS标准收发器逐步统一财务公司与境内外银行数据交互标准,并将CIPS产品优势与金融数据中台建设相结合,先后完成CIPS跨境汇款、支付透镜、账户集中可视、信用证、同户名资金调拨、跨行下拔、全额汇划等多项全国首发业务,不断丰富CIPS应用场景,开创“数据中台+CIPS”创新之路。
近年来,通用技术财务公司协同跨境清算公司及相关国际组织,积极做统一金融数据标准的推动者和人民币国际化的践行者,获得了跨境清算公司颁发的“跨境人民币推广先锋企业”称号,为构建全球网络空间命运共同体贡献一份力量。
6.2 数据图书馆
数据资产管理正成为数据管理的新趋势,它推动了数据管理工作向数据价值转化,以数据资产为导向的数据管理工作可以串联起元数据、数据标准、数据模型、数据质量、数据安全等各项管理工作。我司对数据资产做了详细的盘点,综合考虑补充完善数据资产信息、业务视角确定、行业模型建立、数据分类分级、数据共享、数据认责、数据脱敏、数据质量、业务流程、业务实体等方面,形成了财务公司数据图书馆。
就像现实中的图书馆的目录一样,数据图书馆将公司所有业务归纳总结为11个金融业务类别,每个类别下对应若干具体的数据资产。用户可以从数据图书馆中浏览数据资产的信息,包括资产的各个属性的技术信息、业务信息、血缘信息、分类分级信息、以及数据服务信息。用户可以根据血缘信息,知道每个数据来源的系统和源表字段。同时,打通资产目录和数据分析工具的壁垒,用户可以直接在数据图书馆选择想看的资产后,进入数据分析工具——灵活分析,这里可以根据自己的需要,筛选数据维度、日期、成员单位等信息,实现数据合并、拆分、生成统计图等功能,实现业务资产一体化。这里还会根据岗位不同,结合分类分级,将一些密级数据脱敏,避免数据泄露。除此之外,就像在图书馆一样,你既可以选择直接在图书馆看,也可以将书籍借走。数据图书馆支持一键申请数据资产,生成API接口,经过审批后,即可完成数据共享服务。
6.3“标准-模型-质量”管理体系
数据质量是通用技术财务公司重视数据治理的重要驱动因素,公司经过多年实践,形成了自己的一套“标准-模型-质量”管理体系。
首先,数据治理委员会根据公司业务需要和监管要求,发布公司数据标准,此标准包含业务、技术和管理属性。此标准的新增、变更和废止体现在“金融数据魔方”的数据标准模块。接下来就是对源头系统的落标率进行监控,这里需要根据源头系统的不同建立逻辑模型。有了各系统对应的逻辑模型后,就可以对源头系统每个字段进行关联。首先系统根据财务公司数据库统一命名规范进行匹配,生成系统命名落标率,然后再人工匹配那些对不上的字段,最终实现字段匹配,生成每个标准对应系统的落标率。
有了标准和对应的源头系统表后,系统会根据标准的技术属性,对源头数据的长度、是否为空、格式、枚举值等基础规则自动校验。还有一些复杂的业务规则,则通过人工使用ETL工具配置,实现校验。校验后会生成校验结果,校验结果若有问题则根据配置的负责人分发整改。管理人员也可以在数据质量页面选择时间,生成某个时间段的数据质量报告,报告可作为绩效评定指标。整个“标准-模型-质量”管理体系确保了公司数据质量,并能够实时监控,问题早发现早处理,为监管报送和各种数据分析应用提供了坚实的数据基础。
6.4 数据血缘全景图
数据从前台到后台,对业务人员来说是一个从白盒到黑盒的过程。如何将整个清洗加工和各种复杂的逻辑生成数据资产的过程展现,一直是数据治理中的一大难题,这其中有技术因素,也有各种人力成本的限制。“金融数据魔方”则发挥现有最前端的技术,最大程度地节省人力成本,实现了数据血缘全景图。数据血缘在各处的数据治理都很常见,“金融数据魔方”则在血缘的基础上,增加每一个字段的校验规则,做到业务好理解,运维易使用。业务人员可以通过血缘知道每一项数据资产对应的是自己的什么业务属性,还可以知道目前在这个字段上都配置了哪些校验规则,这样如果数据资产的数据出现问题,责任人可以第一时间找到问题所在。运维人员在解决问题时,也可以根据数据血缘全景图非常容易地找到涉及到哪些表哪些字段。这两方面极大地提升了报送数据处理的时效性,缩短数据使用者解决问题的时间。除此之外,每个数据资产负责人还可以清楚地了解自己的资产都有哪些,并随时完善校验规则,进一步提升数据质量。